Majority of the applications require full-text search in order to provide better user experience for their consumers. But if the data is in the normalized form in a RDMBS system or in a flat file its quite hard to achieve better user experience with full-text search. We need a better way to do search in our applications with minimum infrastructure and development effort.Lucene helps with that.
Lucene is a powerful full-text search Java library that lets you add search to your application easily. Lucene builds an inverted index which will allows us to search through that index very quickly.Here is how you can get started with it.
Dependencies
Inorder to add Lucene library to your Java application add the following dependencies to your application pom assuming your application is maven based, otherwise you may need to download the latest lucene jars and add it to your classpath.
These will have all the APIs required to build an inverted index.
Concept
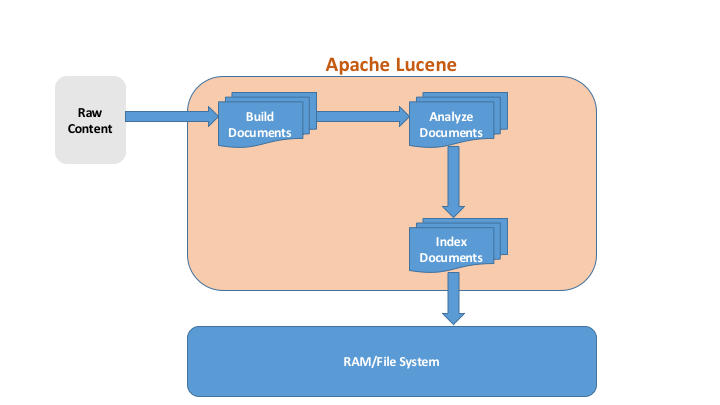
Lucene does the following while indexing text.
- Analyze the input text.
- Builds Documents.
- Index Documents.
- Write index on to a file system or memory.
Here is the simple diagram which explains the flow of Lucene indexing.
Implementation
Now lets get into the code to see how it works.
-
Analyze: Analyzers analyze the input text and apply any filters like StopFilter/LowerCaseFilter etc… so that this will eliminate any english stop words like the, an and have etc…
You could also extend Analyzer to implement you own analyzers.
-
Build Document: A Document is a primary entity in the Lucene index. Lucene expects a Document to be build and send it to the Analyzers where it will build the inverted index. A Document consists of the Fields which will be returned when searching the document. So whatever the data you want to return when searching needs to be added to the Document.
Check the Field implementations for various use cases about adding content to a Document.
-
Index Documents: Once you created Documents now its time to add them to the IndexWriter to write them into the file system/memory.
IndexWriter expect a Directory and IndexWriterConfig before writing any index. We can various output directories based on the implementations of it like FSDicrectory/RAMDirectory/NIOFSDirectory. Looks for various implementations and choose the right one for your use case. MMapDirectory is preferred check here for explanation.
After creating an IndexWriter add the Documents to it by using addDocument(Docuemnt) method.
-
Write Index: Once the index is analyzed and build out its time to persist that into file system/in memory as per for Directory implementation used. If its RAMDirectory its going to be persisted into memory or if its FSDirectory then it will be saved onto the local file system when you do commit(). You may need to close() the writer for graceful shutdown of resources but for performance reasons in production code you may reuse single writer to index and write the index.
After you have done all these you will be able to write the index and you may check the index files in the configured path to make sure its indexing. You may not read the file contents but you can see some files created in the file system.
If you have any questions or comments please post down here, happy indexing with Lucene.